Last updated on August 25th, 2025 at 03:34 pm
For TPMs, SDMs, and CTOs exploring AI/ML strategy without getting lost in the math
In today’s tech landscape, Artificial Intelligence(AI) is an architectural shift that redefines how systems behave and scale. As a technical leader, your job isn’t to build the model yourself, but to understand its constraints, opportunities, and implications to contribute meaningfully to strategy and roadmap decisions. Without a foundational grasp of Machine Learning(ML), you’re flying blind when it comes to trade-offs, technical debt, and roadmap prioritization.
I learned this firsthand while leading engineering and programs in Amazon’s Robotics org, where our teams trained convolutional neural networks to understand items through computer vision, enabling robots to handle items, then moving on to lead Amazon’s social content teams which had to vet all creator text, images, music, videos before they could be published. Two very different ML approaches and applications. Despite having no AI/ML background when I first joined Amazon, I had to quickly ramp up—understanding concepts like supervised learning, classification, regression, model training pipelines, inference latency, and data labeling workflows. It became clear that managers and TPMs supporting ML teams need more than surface-level understanding. It might be tempting to quickly research the latest AI trends alone, but my advice is to start simple while simultaneously ramping up on the specific use-cases for your team.
Artificial Intelligence is a broad field focused on building machines or systems that can simulate human intelligence.
Machine Learning is a subset of AI that focuses specifically on enabling machines to learn from data without being explicitly programmed.
This article aims to give you a high-level understanding and introduces you to foundational ML terms so that you can quickly classify what kind of solution you are assessing from the standpoint of an executive leader/ manager/ TPM.
Introduction to ML
Machine Learning is the process of training a model to make useful predictions or generate content(text, audio, video, images) from data. A model is a mathematical relationship derived from input data that the ML system uses to make predictions.
In the past, to predict complex outcomes like the weather or the listing price for a house, we would use layers of complex equations, perform multiple step functions to transform the data and perform massive computations. In contrast, for a ML solution, large amounts of data are fed to a model so that it finds the connections and learns the mathematical relationship in the data that leads to certain outcomes. Traditionally, programming uses data and algorithms to produce results. Machine learning creates the algorithms using data and results. To make predictions, the model must first be trained. We discuss this in more detail in subsequent sections.
“Machine Learning is a subfield of computer science that gives computers the ability to learn without being programmed” – Arthur Samuel, IBM Journal of Research and Development, Vol. 3, 1959.
Is ML the Right Tool for the Job?
You should determine if an ML approach is beneficial before collecting data and training a model. Ask these key questions:
What is the product goal?
Be specific on the real-world outcome you want to achieve. Does your product need to predict rain, summarize a review, recommend the next video, generate a logo etc.
What kind of solution fits best?
Determine if a predictive ML solution(that generates a numerical or classification output), a generative AI solution or a non-ML solution works best for your use-case as covered in the types of ML solutions section below.
Can a non-ML benchmark set the bar?
Try solving it without ML first to set cost, quality, and speed expectations. The ML solution will need to meet or exceed to be considered beneficial.
Do you have the right data?
Ensure that your dataset is large, diverse and contains features(inputs) with high predictive power, has correct labels(what you want to predict) and features that are available at the time of prediction. This is necessary to even consider a ML solution.
Framing the ML Problem Like a Leader
Once you’ve validated that ML is a good fit:
- Define the outcome: What exactly should the model do – Predict, classify, generate? Examples:
– Generate a business logo versus generate a variety of designs with each one optimized for different media use-cases
– Calculate rain for a zip code versus predict whether it will rain in the zipcode
– Predict if transaction was made by card owner versus identify fraud transactions
– Predict whether a user will view a video versus recommend a set of next videos to watch.
– Each option is slightly different and will determine what features and labels you use. - Identify the model output: Is it a number, a category/class(es), natural language output or content(image, video, audio)?
- Understand the problem constraints: If your outcome is different based on different thresholds and you are using supervised learning, determine if those thresholds are static or dynamic. You will need to ensure your labelled dataset used for supervised learning is based on these threshold limits if they are static.
- Set success metrics: They should reflect the desired business outcomes of the ML implementation. These are different from your model evaluation metrics( precision, recall, AOC). Examples are that users spend more time on your app, or that efficiency increased, costs reduced etc. Differentiate between model evaluation metrics and business KPIs. This will help you understand whether improving the model’s performance is getting you closer to your success criteria. If your model has low evaluation metrics but you are still moving towards your success metrics, it indicates that investing in improving model performance will likely lead to improved success.
- Estimate ROI: Is the business impact worth the engineering and maintenance cost of the ML solution. For each retraining round, evaluate if the cost and resources used will justify the improvement of the model.
Engineering Paths in ML
From a leadership perspective, most engineering teams working with ML fall into three broad categories. Based on my experience leading ML programs at Amazon, here’s how I define them:
1. ML Infrastructure Engineering
These teams build the core platforms and tools that power machine learning—think of services like SageMaker, Glue, or Vertex AI. The focus is on creating scalable, reusable infrastructure for data ingestion, training, deployment, and monitoring.
Key trait: Heavy engineering, lighter on ML—ML informs feature requirements, but the product is the infrastructure itself.
2. ML Operations (MLOps)
These teams implement, customize, and manage ML tools for specific use cases. They handle real-world ingestion, transformation, labeling, deployment, and monitoring of models developed by scientists—or customize pre-trained models.
Key trait: Engineering-heavy, but deeply tied to the ML use case. Leaders must understand the full model lifecycle, versioning, rollback plans, labeling workflows, feature extraction, and both model and system metrics.
3. Integrated AI/ML Engineering
These are embedded engineers working closely with ML scientists to productionize models, refactor research code, run experiments, and fine-tune/customize models. This model is common in startups and high-velocity teams.
Key trait: High-touch collaboration with scientists. Requires deeper ML literacy to ensure implementation doesn’t compromise model integrity or business outcomes.
Regardless of category, every engineering team that owns ML solutions will touch MLOps. Most will use cloud-native ML tools (AWS, Azure, GCP) or integrate GenAI services like LLMs. Some engineers will also engage in model-level work, especially in smaller or specialized teams. Understanding which category your team falls into will help you make better architectural, resourcing, and roadmap decisions. We’ll explore each in detail in upcoming posts.
Behind the Scenes: ML Data Pipelines
A lot of the upfront work in implementing a model is in creating the data pipelines it needs for training(used for prediction on training data) and inference(used for prediction on live data). The data pipeline work needs to be prioritized as it is an essential building block. The recommendation is to start simple with a few features for the model and then determine if a complex model is justified.
A typical ML pipeline spans data ingestion, cleaning, transformation, feature engineering, storage and delivery to training environments, often requiring orchestration across batch and real-time systems. Common tools in the stack include Apache Kafka or Amazon Kinesis for streaming ingestion, Apache Airflow or Prefect for orchestration, Spark or Pandas for transformation, and AWS S3, Snowflake, or BigQuery for scalable storage. Teams often underestimate the effort to clean and label data, handle schema changes, and ensure reproducibility. Technical debt can quietly accumulate when pipelines aren’t versioned, monitored, or modularized. The key is designing with observability, reusability, and fault tolerance in mind from day one. It is a living, evolving system that directly impacts the long-term quality and trustworthiness of your ML inferences.
Below is a table of some of the different tools that exist.
| Category | AWS | Azure | Google Cloud | OCI |
| ETL / Orchestration | AWS Glue, Step Functions | Azure Data Factory | Cloud Dataflow, Cloud Composer (Airflow) | OCI Data Integration |
| ML Workflow Management | Amazon SageMaker Pipelines | Azure ML Pipelines | Vertex AI Pipelines | OCI Data Science Pipelines |
| Data Processing | EMR (Spark), AWS Glue | Azure Databricks, Synapse | Dataproc (Spark), BigQuery | OCI Data Flow (Spark) |
| Storage | Amazon S3 | Azure Blob Storage, Data Lake Storage | Google Cloud Storage, BigQuery | OCI Object Storage |
| Notes on Usage | Highly modular, widely adopted | Strong Microsoft integration, hybrid-friendly | Unified AI + data stack, BigQuery synergy | Strong enterprise tools, growing ML focus |
The team also needs to implement metrics that will be used to monitor and alert on model performance, inference server issues, skew in training – serving distribution where the model might be predicting on data distributions that it has not been trained on or if it is predicting outside a distribution range seen during training. Trained models exist for a variety of use-cases and can be re-used as long as the features and labels match exactly. If they don’t, the predictions will be poor. We will go deeper into model metrics in future posts.
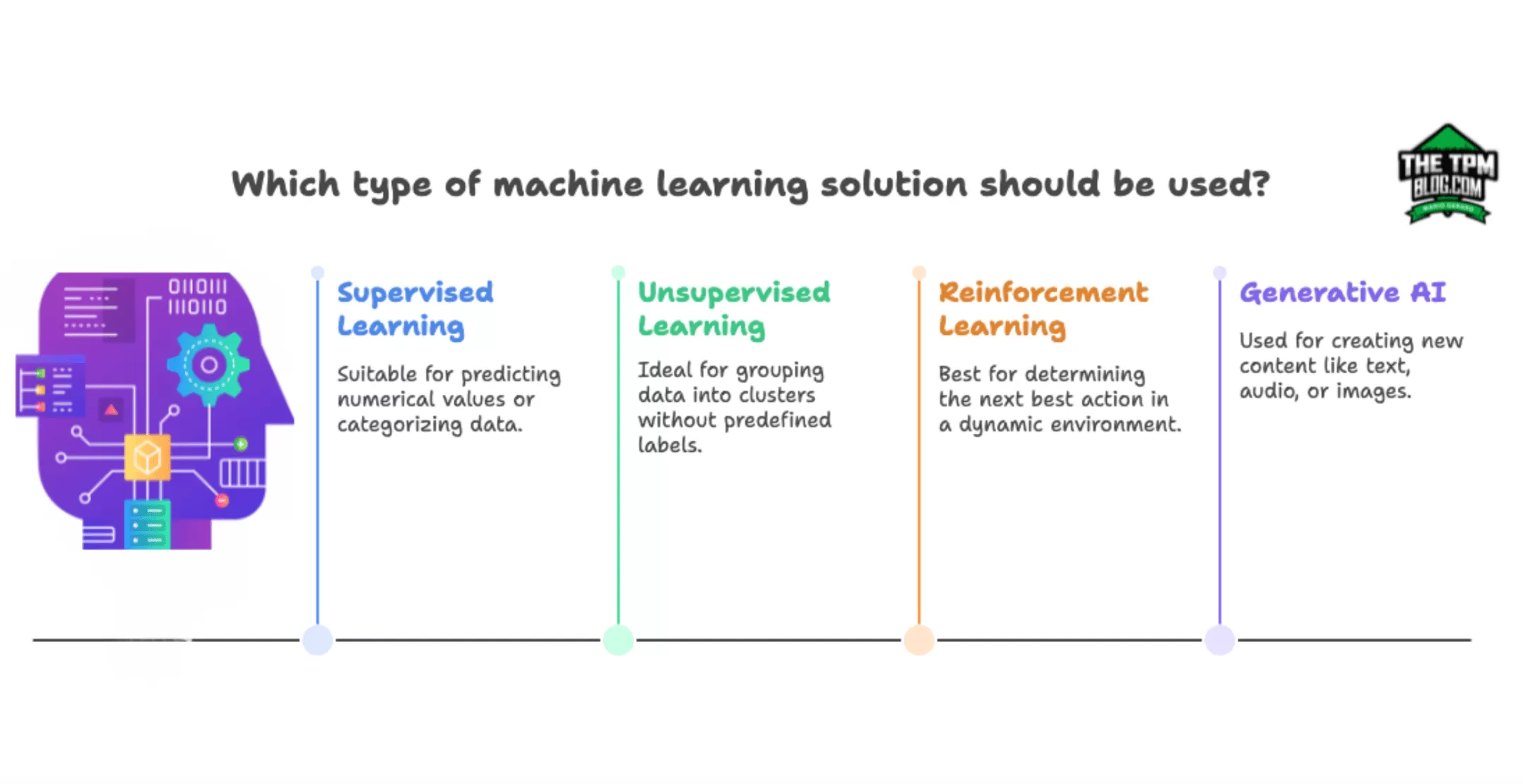
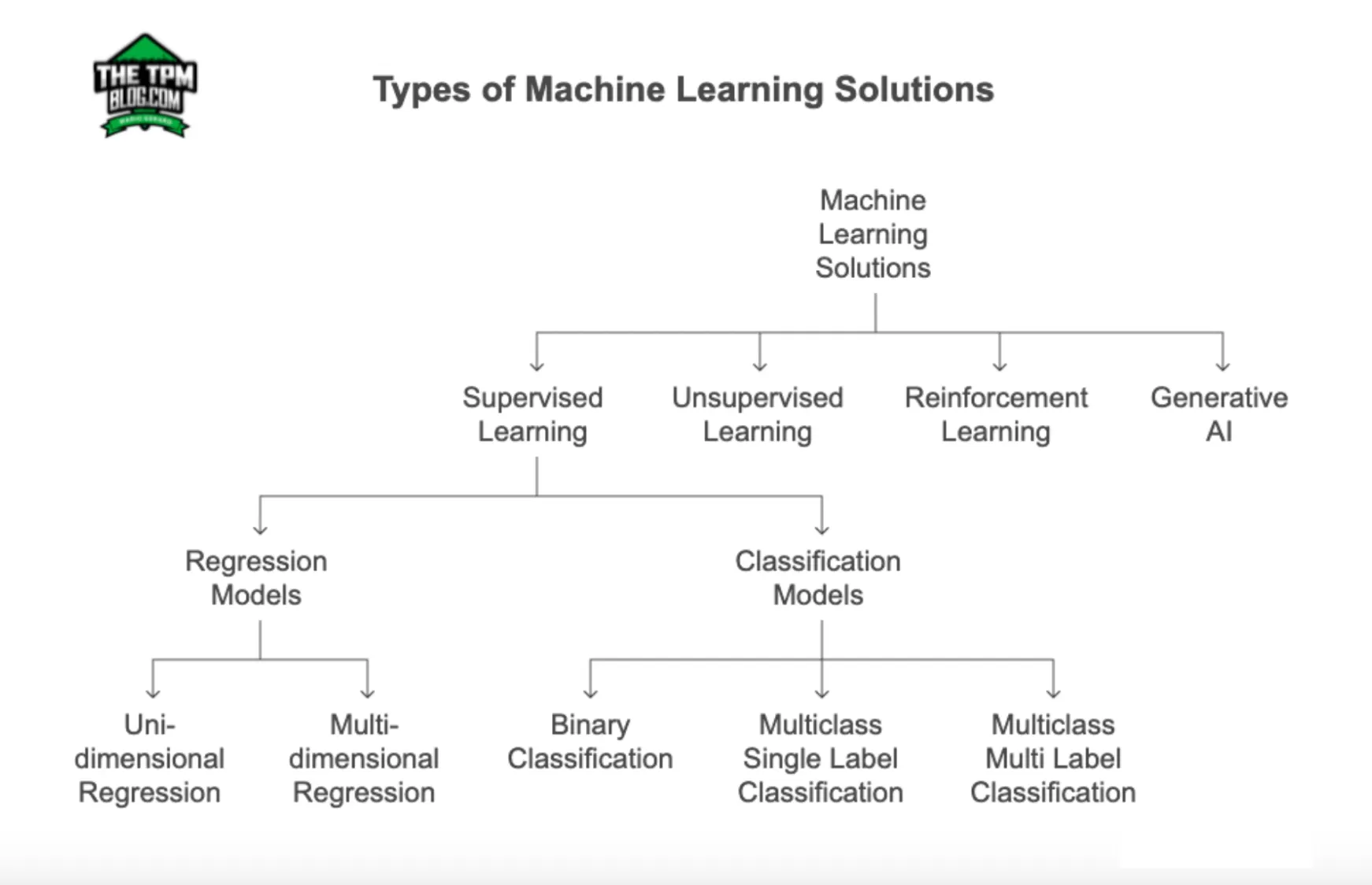
ML Basics: Types of ML Solutions
If you already know the value or category you want to predict, you will likely use supervised learning models for your solution. If you want to learn if your dataset contains segmentations or groupings, use unsupervised learning. To create new, unique content , you would use Generative AI.
Machine learning has two main phases:
- Training:
Input data are used to calculate the parameters of the model. The goal of training is to create a model that can answer a question. - Inference:
The “trained” model outputs correct data from any input. Inference is when the trained model is used to infer (predict) values using live data. Like putting the model into production.
We dive into the different approaches to train a model below.
Supervised Learning
In supervised learning, the model finds connections that produce the correct answer. The model makes predictions after seeing lots of data labelled with correct answers. It then discovers the connections between the elements in the data that produce correct answers. The output can be a numerical value or single/multiple categories.
During training, the model finds the best solution by comparing its predicted value to the label’s actual value. Based on the loss (difference between predicted and actual value), the model gradually updates its solution. The model works its way through each example in the training dataset to learn the correct relationship between the features and the label.
This is like studying old SAT exam papers and question-answer banks to prepare for the exam.
Once trained, the model is evaluated to determine how well it learned. Evaluation is done with a labelled evaluation dataset that the model has not seen before. However, the model is only given the features and not the labels that indicate the correct answer. The model’s prediction is then compared to the actual true labelled values to see how well it performed. The performance is used to decide on retraining needs such as adjusting features or training on a larger dataset, or whether to deploy the model to the real-world. In a real-world scenario, the model makes predictions called inferences on unlabelled data that only has features.
Regression Models
Regression models produce a numerical value as the output. Examples are predicted home prices, temperature, drive time etc.
Regression models are unaware of product defined thresholds. Use-cases that employ a regression model should be cautious if small differences in the model predictions significantly alter the outcome or product behavior. In such cases, a classification model might be a better choice, as it produces thresholds by default based on the loss function. Alternatively, you could use dynamic thresholds that you set within your application instead. This way, you can easily update the thresholds while the model continues to make reasonable predictions that represent the final decision or outcome for your problem statement such as flight price is higher than normal for this route etc.
There are multiple concepts such as linear regression, logistic regression, uni-dimensional regression, multi-dimensional regression that we are not covering in this article to keep it readable at a beginner level. Future articles will address these or research them as needed.
Classification Models
Classification models predict the likelihood of belonging to a category. The output is typically a probability score, which gets mapped to a final decision such as : is this email spam or not, is there a person in the image, or is the forecast snow or sleet. There are several types of classification problems: binary classification handles two categories (e.g., “yes” or “no” for nudity detection); multiclass single-label classification handles more than two categories, but each input maps to only one class (e.g., identifying whether an image shows snow, rain, or hail); and multiclass multi-label classification allows one input to belong to multiple categories simultaneously (e.g., tagging a photo with “person”, “car”, and “daylight”).
Unsupervised Learning
Unsupervised learning models make predictions by being given data that does not contain any known correct answers. It identifies patterns in the data and infers its own rules, while not having any hints on how to categorise each piece of data. These models use a technique called ‘Clustering’ by finding data points that demarcate natural groupings. The output is a pattern or grouping found within the data. Examples of such outputs would be grouping of customers based on spending behaviour, finding anomalies such as unusual credit card transactions etc.
‘Clustering’ is different from ‘Classification’ as the categories are not defined beforehand. The generated output clusters can be named afterwards based on the human understanding of the dataset, but the model does not label it.
Reinforcement Learning
Reinforcement learning models generate a strategy or policy to maximize rewards. They make predictions learning from trial and error by getting rewards or penalties based on the actions performed within an environment based on its predictions. Such models are used to train robots or for stock trading. The output is not a numerical value, class or cluster. The output is the best next possible action(s) to be taken in a product. Examples of this output would be ‘move left’, ‘grab item with force Y’, ‘buy/sell hold stock X’.
Generative AI
Generative AI models generate content from user input. It can take a variety of inputs and generate text, audio, video, image output. GenAI learns patterns in the data with the goal to produce new, unique but similar data. Examples of such output could be musical compositions, memes, article summaries, social media thumbnail etc.
GenAI models can be initially trained using an unsupervised learning approach, to learn how to mimic the data it is trained on. It can then be trained further using reinforcement learning or supervised learning on a specific task the model might be asked to perform such as summarizing an article or editing photos. GenAI can also be used to implement a predictive ML solution(regression/classification) as it has a deeper understanding of Natural Language Processing(NLP).
In most cases, you won’t train your generative AI model as it requires massive amounts of training data and computational resources. Typically, you customize a pre-trained GenAI model. Generative AI models (like ChatGPT or DALL·E) start with a model that already knows a lot about the world (a pre-trained model), and then they are fine-tuned or customized for specific tasks or topics
Customization techniques for GenAI models:
- Distillation: Create a smaller version of a larger model by generating a synthetic dataset and using it to train the smaller version. This changes the model’s parameters.
- Parameter – Efficient tuning: Train an existing model on a specific task by using a training dataset that contains examples of the type of output you want to produce. This changes the model’s parameters.
- Prompt Engineering: Use NLP instructions to give the model an example to get it to perform a specific task. This does not change the model’s parameters.
Understanding Data in Supervised Learning
The data used to train models can be text, numbers, values(eg: pixels), waveforms, audio files, images etc. Labelled datasets consist of examples that contain both features and labels. Unlabelled datasets consist of examples that contain only features but no labels.
Features are values that the supervised model uses to predict the label. Examples would be latitude, longitude, zipcode, temperature, speed limit etc., depending on the use-case.
Labels are the correct answer or value the model is expected to predict. Examples would be the amount of rainfall in cm, drive time in minutes, category like isSpam, category like ‘hasPoison’ etc.
A good dataset is both large in size and diverse in the range of examples it covers. The labels in the data need to be reliable and correct. It can also be categorized by the number of features it contains. Datasets with more features can help the model discover additional patterns and make better decisions as long as they have good predictive power.
For a model to make good predictions, the features in your dataset should have a high co-relation to the label (correct outcome), be representative of the real-world and be available at the time of prediction.
The ML engineer/scientist can select or adjust features the model uses during training to see if the model performs better with or without it. You can automate finding a feature’s predictive power by using algorithms such as Pearson’s correlation, Adjusted Mutual Information(AMI) , Shapley Value etc.
Proxy Labels are used when you cannot directly measure what you want to predict such as if a user will find a video helpful or not. There is no label for this, so the proxy label can be whether the user liked a video or shared it. They have disadvantages as there is no guarantee if the proxy label might exist (eg: user does not take any action).
Conclusion
You don’t need to be an ML expert to lead ML work as a software manager, TPM or product manager. However, to build trust with your engineers, scientists, reduce risk in your roadmap, and unlock meaningful insights from your data – you do need to understand the fundamentals and experiment. Start small, ask sharp questions, and use this series as your blueprint.
Ready to rock your TPM Interview?
A detailed interview prep guide with tips and strategies to land your dream job at FAANG companies.
Author